



Five French OCR solutions compared for extracting your document data with full GDPR compliance, hosted on servers in France.
Comparatives

Dernière mise à jour :
November 3, 2025
5 minutes
What if your documents knew where to go without you having to tell them? Document management is evolving. Today, technologies like Intelligent OCR can recognize, classify, and route documents automatically, even when they are complex or multilingual. In this article, we put a classification engine to the test on a real-world use case: identity documents from multiple countries. Discover how to automate document sorting with precision, without any manual setup.
How to Accurately Classify Documents with Intelligent OCR? A Concrete Use Case on ID Documents
%20(1)%201.webp)
Document classification, automatic categorization, intelligent sorting... all refer to a key capability in a professional world overwhelmed by documents. Whether it's payslips, supplier invoices, contracts, or identity documents, the need to efficiently organize and sort information has become critical across many industries.

Banking, insurance, healthcare, logistics, human resources, and even the public sector all face a massive influx of heterogeneous and often sensitive documents that must be processed quickly and accurately.But manual document handling quickly reaches its limits: it’s slow, error-prone, and labor-intensive.
This is where Intelligent Document Processing (IDP) technologies come into play.Artificial intelligence, machine learning, and optical character recognition (OCR) now make it possible to automate the analysis and classification of large volumes of documents.

It refers to the ability to automatically recognize the type of a document (e.g., “contract,” “passport,” “invoice,” etc.) without human intervention, in order to route it to the appropriate workflow or database.
This step is crucial in any document automation process, as it directly impacts the subsequent phases such as data extraction, validation, and archiving.
In this article, we illustrate this capability through a real-world use case: the automatic classification of multilingual identity documents (national ID cards, passports, driver’s licenses, residence permits) using the Koncile solution.
Koncile is an intelligent OCR software specialized in extracting accurate data from complex documents such as contracts, payslips, financial statements, or transport documents.
Our goal is simple: to provide a fast, reliable system with no manual configuration required.
This makes it an ideal OCR data extraction software for teams looking to reduce manual workload and improve consistency across large volumes of documents.
In this example, we tested our automatic classification engine on a set of identity documents (national ID cards, passports, driver’s licenses, residence permits) from multiple countries.
We used a set of 18 documents (driver’s licenses, residence permits, national ID cards, passports), including:
Test Dataset Composition
Objective: Evaluate the performance of our system without any contextual guidance.
Here are the steps of this first test:

2- Add the available extraction templates
In this first test, we do not provide any description of the type of information to retrieve from this folder.We simply add the document templates to be extracted, using the existing extraction models already created in the application.
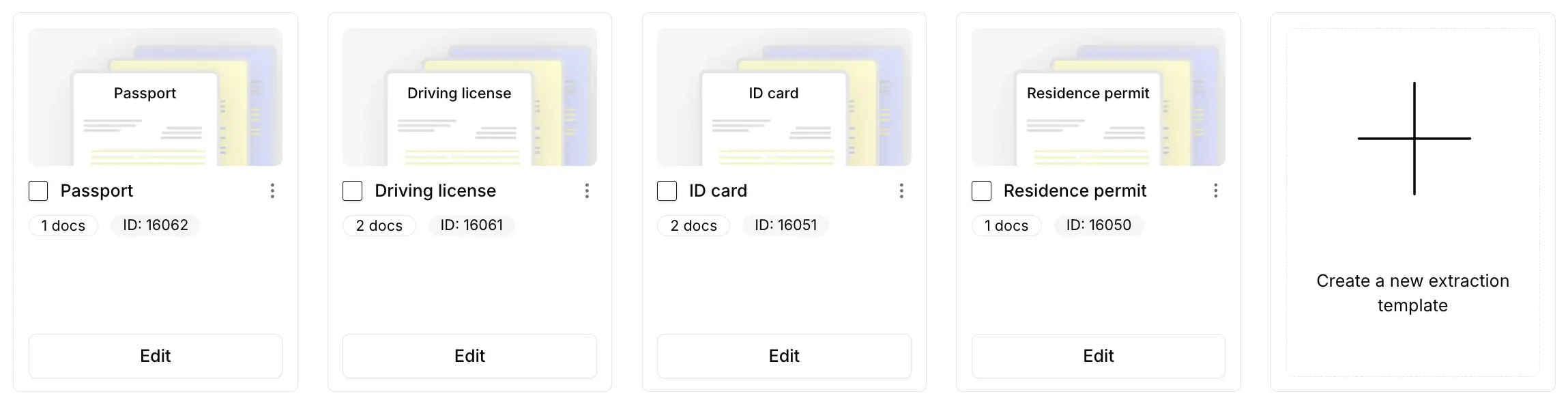
3- Import the different types of documents without classification
In this phase, we performed a raw import of all 18 identity documents, without applying any sorting rules or specific instructions.
The goal is to observe the default behavior of Koncile’s auto-classification engine when faced with a collection of diverse document types.
We aim to assess whether the engine is capable of:

Test 1 Results
Despite the absence of explicit instructions, our engine was able to identify the document types (ID card, passport, driver’s license, etc.) and apply automatic classification based on their visual and textual features.
Each document was accurately categorized, despite the diversity of languages used.
Soit un taux de réussite de 100%.
Objective: Test the automatic differentiation between French and British identity documents, also without any contextual indication.
1- Creation of Two Identity Document Folders
For this new test, we are increasing the level of complexity by creating two separate folders: one containing French identity documents and the other containing documents exclusively from the United Kingdom. As in the previous test, classification will rely solely on the folder name and model name, with no additional description provided.
2- Adding the Available Extraction Models
As in the previous step, we add the various extraction models to both folders.

3. Import of various document types without predefined classification
Test 2 Results
With 15 documents correctly classified out of 18, the engine achieved a success rate of 83.33% in this scenario.
Driver’s licenses and residence permits were perfectly recognized (4/4 and 3/3 respectively).
The observed errors involved two national ID cards (one British and one Italian) that were incorrectly placed in the French folder, as well as one Italian passport, also mistakenly classified as French.
These errors are understandable, particularly in the case of the Italian documents (which account for 2 out of the 3 misclassifications), since no dedicated category for Italy had been created at this stage, and no explicit instruction was given to exclude foreign documents.
The engine therefore classified these items based on linguistic or visual similarity, in the absence of precise guidance.
Objective: Observe the impact of a descriptive prompt on classification accuracy.

Prompt for the folder "Foreign Identity Documents: "Extract only identity documents issued by official foreign authorities, excluding any documents issued by France. The language used (French, English, or others) does not matter, all documents originating from countries other than France must be included: passports, driver's licenses, identity cards, etc. French documents (i.e., issued by French institutions) must always be ignored, even if written in English or any other language."
Prompt for the folder "French Identity Documents: "Extract only identity documents issued by official French authorities. All documents must have been issued by French institutions: passports, identity cards, driver’s licenses, residence permits, etc. Documents issued by foreign countries must always be ignored, even if they are written in French."
Test 3 Results
This third test of automatic identity document classification shows a clear improvement compared to the previous one.
During the second test, the success rate was 83.33%, with several misclassifications for national ID cards.
In this new iteration, all 18 documents were correctly classified, resulting in a 100% success rate.
This significant improvement can be attributed mainly to the addition of a contextualized prompt, which enabled the tool to interpret the documents more accurately.
By providing a clear framework and explicit instructions, the model’s performance improved considerably, especially on cases that had previously been prone to errors.
In cases that are even more complex than the one presented here, such as documents lacking explicit labels, with few distinctive visual features, or highly technical content several optimization strategies can be explored to further enhance classification accuracy.

Automated document classification is no longer just a technical feature, it is a strategic asset for any organization dealing with large volumes of heterogeneous documents.
Solutions that integrate advanced OCR are essential to enable automation and reliability from the very first step of document processing.
As demonstrated by our tests, our solution delivers high accuracy even without prior configuration, thanks to its advanced visual, textual, and contextual analysis capabilities.
By integrating descriptive prompts or refining sorting categories, even higher performance levels can be achieved, making document management smoother, more reliable, and significantly less dependent on human intervention.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Five French OCR solutions compared for extracting your document data with full GDPR compliance, hosted on servers in France.
Comparatives

Koncile's MCP OCR server connects AI agents to intelligent document extraction. 24 tools, structured data output, 15-minute setup. Try it free or self-host.
Feature

Document fraud detection with OpenCV in Python: real tests and limitations.
Comparatives
.png)


